Abstract
Symmetry and asymmetry play vital roles in prediction. Symmetrical data, which follows a predictable pattern, is easier to predict compared to asymmetrical data, which lacks a predictable pattern. Symmetry helps identify patterns within data that can be utilized in predictive models, while asymmetry aids in identifying outliers or anomalies that should be considered in the predictive model. Among the various factors associated with storms and their impact on surface temperatures, wind speed stands out as a significant factor. This paper focuses on predicting wind speed by utilizing unified hybrid censoring data from the three-parameter Burr-XII distribution. Bayesian prediction bounds for future observations are obtained using both one-sample and two-sample prediction techniques. As explicit expressions for Bayesian predictions of one and two samples are unavailable, we propose the use of the Gibbs sampling process in the Markov chain Monte Carlo framework to obtain estimated predictive distributions. Furthermore, we present a climatic data application to demonstrate the developed uncertainty procedures. Additionally, a simulation research is carried out to examine and contrast the effectiveness of the suggested methods. The results reveal that the Bayes estimates for the parameters outperformed the Maximum likelihood estimators.
1. Introduction
Wind is the force that converts air pressure into air movement, causing the speed of the wind to decrease as air pressure increases. When a mass of moving air slows down, its kinetic energy or momentum is converted into static atmospheric pressure. This relationship indicates that higher wind speeds correspond to lower air pressure measurements. In addition to transporting hot or cold air, wind introduces moisture into the atmosphere, resulting in changes in weather patterns. Therefore, changes in wind conditions directly impact the weather. The direction of the wind is influenced by differences in air pressure. Wind flows from areas of high pressure to low-pressure zones, and the wind’s speed determines the degree of cooling. The UHCS, a generalised Type-I and Type-II HCS, was first introduced by Balakrishnan et al. [1]. The following is a definition of it: Let and be values within the range , where is greater than , and let r and K be integers such that . The test ends at min{max {} if the Kth failure occurs before time , where represents the failure time of the rth unit. The test ends at the earliest possible time between and if the Kth failure occurs between and . If the kth failure occurs after time , the experiment is terminated at , where denotes the failure time of the Kth unit. By employing this censoring scheme, we can ensure that the experiment concludes within a maximum duration of with at least K failures. In such case, we can assure exactly K failures. The Burr-XII distribution was first developed by Burr [2] and has been effectively used with a wide variety of observational data in many different fields. See Shao [3], Wu et al. [4] and Silva et al. [5] for more information on Burr-XII’s applications. There are several reasons for choosing the Burr distribution. Firstly, it encompasses only positive values, making it particularly suitable for modeling hydrological or meteorological data. Secondly, it possesses two shape parameters, enabling its adaptability to different samples due to its ability to cover a wide range of skewness and kurtosis values. For further discussion on this aspect, see Ganora and Laio [6]. Thirdly, the Burr-XII family is extensive and includes various sub-models, such as the log-logistic distribution. Cook and Johnson [7] utilized the Burr model to achieve improved fits for a uranium survey dataset, while Zimmer et al. [8] explore the statistical and probabilistic properties of the Burr-XII distribution and its relationship with other distributions commonly used in reliability analysis. Tadikamalla [9] expanded the two-parameter Burr-XII distribution by introducing an additional scale parameter, resulting in the TPBXIID. Since then, the applications of the Burr-XII distribution have received increased attention. Tadikamalla also established mathematical relationships among Burr-related distributions, demonstrating that the Lomax distribution is a special case of the Burr-XII distribution, and the compound Weibull distribution generalizes the Burr distribution. Furthermore, Tadikamalla showed that the Weibull, logistic, log-logistic, normal, and lognormal distributions can be considered as special cases of the Burr-XII distribution through appropriate parameter choices. The TPBXIID offers significant flexibility by incorporating two shape parameters and one scale parameter into its distribution function, allowing for a wide range of distribution shapes. The TPBXIID is defined by the following cdf:
and the pdf is given by:
The survival function can be obtained as:
and the failure rate function is given by:
where the parameters and determine the shape of the density function, while determines its scale. When is greater than 1, the function has a shape that resembles an upside-down bathtub and is unimodal, with the mode occurring at . In the case where is equal to 1, the function has an L-shape.
The TPBXIID can be reduced to well-known distributions as follows:
The shapes of the pdf, cdf, survival and failure rate functions of the TPBXIID for different values of the parameters , and are given in the Figure 1, Figure 2, Figure 3 and Figure 4.
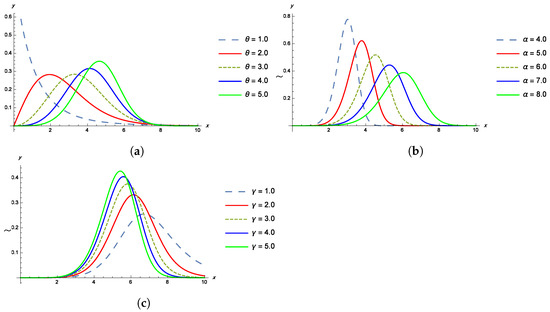
Figure 1.
(a) The pdf of TPBXIID with , and for various values of the shape parameter . (b) The pdf of TPBXIID with , and for various values of the scale parameter . (c) The pdf of TPBXIID with , and for various values of the shape parameter .
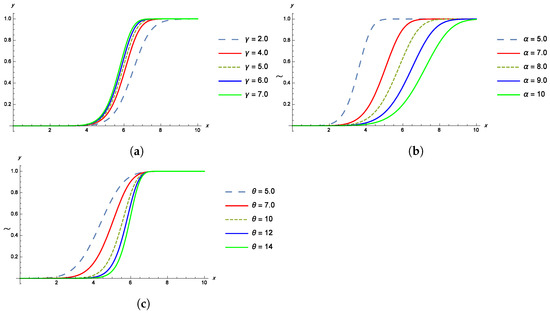
Figure 2.
(a) The cdf of TPBXIID with , and for various values of the shape parameter . (b) The cdf of TPBXIID with , and for various values of the scale parameter . (c) The cdf of TPBXIID with , and for various values of the shape parameter .
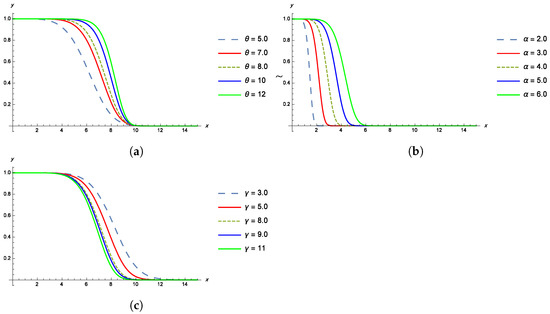
Figure 3.
(a) The survival function of TPBXIID with , and for various values of the shape parameter . (b) The survival function of TPBXIID with , and for various values of the scale parameter . (c) The survival function of TPBXIID with , and for various values of the shape parameter .
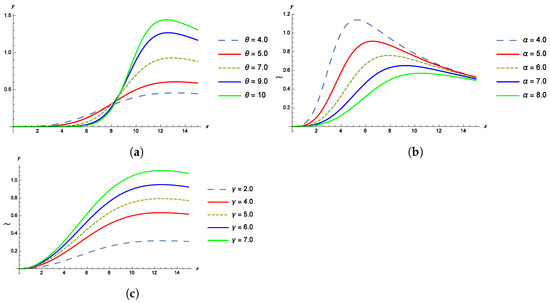
Figure 4.
(a) The hazard rate function of TPBXIID with , and for various values of the shape parameter . (b) The hazard rate function of TPBXIID with , and for various values of the scale parameter . (c) The hazard rate function of TPBXIID with , and for various values of the shape parameter .
Properties of the TPBXIID
- The rth moment about the origin of a random variable Z distributed by a TPBXIID, denoted by , is the expected value of , symbolically,where
- The variance of TPBXIID can be written as
- The quantile of the TPBXIID can be defined as
Belaghi and Asl conducted research on estimating the Burr-XII distribution using both non-Bayesian and Bayesian methods in recent studies [10]. Another study by Nasir et al. [11] introduced a new category of distributions, called Burr-XII power series, which has a strong physical basis and combines the exponentiated Burr-XII and power series distributions. Additionally, Jamal et al. [12] proposed an altered version of the TPBXIID distribution that has flexible hazard rate shapes based on the common Burr-XII distribution.This study has been examined by multiple authors, including Sen et al. [13], Dutta and Kayal [14], Dutta et al. [15], and Sagrillo et al. [16].
Prediction plays a significant role in inferential statistics and is of great importance in various practical domains such as meteorology, economics, engineering, and education greatly rely on prediction for making informed decisions. Many life-testing experiments involve predicting future observations. Several researchers, including Balakrishnan and Shafay [17], AL-Hussaini and Ahmad [18], Shafay and Balakrishnan [19] and Shafay [20,21] have explored Bayesian prediction methods for future observations using various types of observed data.
Recently, Ateya et al. [22] conducted a study on predicting future failure times using a UHCS for the Burr-X model, with specific emphasis on engineering applications. In this article, we address the same problem using UHCS but with additional considerations. Let denote the order statistics from a random sample of size n from an absolutely continuous distribution. Under the UHCS, we run into six situations, which are listed below:
- (I)
- ,
- (II)
- ,
- (III)
- ,
- (IV)
- ,
- (V)
- ,
- (VI)
- .
In each situation, the experiment is terminated at , , , , , and , respectively. Thus, the likelihood function of the UHCS can be expressed as:
In this context, W represents the cumulative number of failures observed in the experiment up to time B (the stopping time point), and and indicate the number of failures that have occurred before time points and , respectively.
The log-likelihood function for Equation (10), can be expressed as follows:
To obtain the parameter estimates, we calculate the first derivatives of Equation (11) as follows:
and
From (14), we obtain the MLE as
Because Equations (12) and (13) cannot be written in closed-form expressions, we propose that the parameters have gamma prior distributions as follows:
The expression
represents the joint prior distribution for the , and The joint posterior density function is obtained from (8) and (16) as follows:
It can be seen that, generating samples of can be achieved easily using any routine that produces random numbers from a gamma distribution. However, the posterior density functions of given and in (18), and the posterior density function of given and in (19), do not have known distributions that allow for direct sampling using conventional techniques. Despite this, when observing the plots of both posterior distributions, it becomes apparent that they exhibit similarities to normal distributions, as depicted in Figure 5. Therefore, we recommend employing the Metropolis–Hastings algorithm with a normal proposal distribution to generate random numbers from these distributions, as suggested by Metropolis et al. [23]. The subsequent sections of this paper are organized as follows: Section 2 examines Bayesian prediction intervals utilizing the UHCS for the TPBXIID. In Section 3, we employ the MCMC technique to derive Bayesian prediction intervals. Section 4 presents an analysis of a real dataset for illustrative purposes. Finally, Section 5 offers concluding remarks.
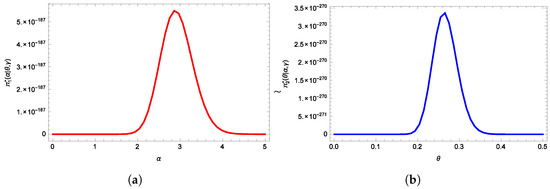
Figure 5.
(a) Posterior density function for and (b) Posterior density function for .
2. Approximate Confidence Interval
The asymptotic variance–covariance of the MLEs for the parameters , , and can be determined by the elements of the negative Fisher information matrix, denoted as . These elements are defined as follows:
Finding exact mathematical formulas for these assumptions is difficult, though. The variance-covariance matrix is therefore calculated as follows:
where , , and represent the estimated variances of , , and , respectively, while , , and denote the estimated covariances between the corresponding parameters. The second derivative is given in Appendix A. Substituting the estimated values , , and into the matrix expression, we obtain the inverse of the asymptotic variance–covariance matrix. Finally, the confidence intervals for the parameters , , and can be calculated as follows:
where is the standard normal value.
3. One-Sample Bayesian Prediction
In this section, we introduce a general approach for computing interval predictions for the future order statistic , which represents the observation, within the TPBXIID framework. These predictions are based on the observed UHCS denoted as , where . For a more comprehensive discussion on Bayesian prediction, please refer to Shafay [20,21]. The conditional density function of given the UHCS can be expressed as follows:
where
with , and , from (25), we get
and, for , we get
with , so, we can get
also, for , we have
with , ,
Finally, for , we have
with , so, we can get
The conditional density functions of , considering the UHCS, can be derived by substituting Equations (1) and (2) into Equations (26)–(29). The resulting expressions are as follows:
and
, , and are given in Appendix C. The Bayesian predictive density function of can be obtained as follows:
where, for ,
with . For ,
with . For ,
with , and for ,
with , for . and are given in Appendix C.
It is evident that, the integrals in (34) is so hard to evaluate analytically. Then, to approximate the , we used MCMC samples generated by using Gibbs within Metropolis–Hasting samplers. The Bayesian predictive for a two-sided equi-tailed % interval of , where , can be obtained by solving the following two equations:
where is computed using the expression:
Here, and represent the lower and upper of the interval, respectively.
4. Two-Sample Bayesian Prediction
We propose a general procedure for calculating interval predictions for the order statistic , where , for the TPBXIID using the UHCS. The marginal density function of the order statistic from a sample of size m drawn from a continuous distribution with cdf and pdf can be expressed as:
where , , and the derivation can be found in Arnold et al. [24].
Substituting the expressions for and from Equations (1) and (2) into the above expression, the marginal density function of becomes:
We can derive the Bayesian predictive density function of , as follows:
It is evident that Equation (43) is challenging to solve analytically, making closed-form solutions impossible to obtain. Thus, we resort to using MCMC samples generated by applying Gibbs within Metropolis–Hastings samplers to approximate as:
By solving the following two equations, the Bayesian predictive of a two-sided equi-tailed % interval for , where , can be obtained:
where is given as in (44), and and indicate the lower and upper, respectively.
5. MCMC Method
In this section, we investigate the application of the MCMC method to obtain samples of , , and from the posterior density function (17). Specifically, we will concentrate on the M-H-within-Gibbs sampling technique, which is explained as follows.
5.1. Estimation Based on Squared Error (SE) Loss Function
The SE loss function is defined as:
where a is a positive constant, typically set to 1. Here, , represents the function to be estimated with respect to , and is the SE estimate of . The Bayes estimator under the quadratic loss function is the mean of the posterior distribution:
where denotes the posterior distribution. The SE loss function is widely used in the literature and is considered the most popular loss function. It possesses symmetry, treating overestimation and underestimation of parameters equally. However, in life-testing scenarios, one type of estimation error may be more critical than the other.
5.2. Estimation Based on Linear Exponential (LINEX) Loss Function
The LINEX loss function, denoted by , is defined as follows:
where represents the difference between the true value and the LINEX estimate , as defined previously. The shape parameter a governs the direction and degree of symmetry. It was introduced by Varian [25] and further explored for its interesting properties by Zellner [26]. When , overestimation leads to more severe consequences than underestimation, and vice versa. In contrast, when a is near zero, the LINEX performs similarly to the symmetric SE loss function. For , the function becomes highly asymmetric, with overestimation incurring greater loss than underestimation. Conversely, for , the loss increases exponentially when , and decreases approximately linearly when .
The posterior expectation of the LINEX (48) is expressed as follows:
Using the LINEX loss function, the Bayes estimate of is obtained as follows:
provided that exists and is finite.
5.3. Estimation Based on General Entropy (GE) Loss Function
Basu et al. [27] introduced a modified LINEX loss function. An alternative loss function that can be considered as a viable substitute for the modified LINEX loss is the GE loss, which is defined as
where the symbol denotes an estimation of the parameter . It is crucial to note that for , a positive error carries greater consequences than a negative error. Conversely, when , a negative error results in more serious implications than a positive error.
The Bayes estimator under the GE loss function is expressed as follows:
provided that exists and is finite. It can be shown that when , the Bayes estimate (52) coincides with the Bayes estimate under the SE loss function. We use the Metropolis–Hasting method with a normal proposal distribution to generate random numbers from these distributions (see Metropolis et al. [23]). Now, we illustrate the steps of the process for the Metropolis–Hasting within Gibbs sampling (Algorithm 1):
| Algorithm 1: Metropolis–Hasting within Gibbs sampling |
|
6. Applications
In this section, we examine actual datasets to demonstrate the practical implementation of the prediction methods discussed earlier. These datasets were obtained from the National Climatic Data Center (NCDC) in Asheville, USA and contain measurements of wind speeds in knots over a 30-day period. Our analysis specifically concentrates on the daily average wind speeds recorded in Cairo city from 1 December 2015 to 30 December 2015. Within this timeframe, we collected a total of 24 observations as follows:
The K-S test was employed to assess the goodness-of-fit of the data distribution to TPBXIID. The K-S distance was calculated to be , which is smaller than the critical value of at a significance level of 5% for a sample size of 24. The corresponding p-value was determined to be . Based on these results, we accept the null hypothesis that the data conform to the TPBXIID distribution, as the high p-value suggests a good fit. Figure 6 displays the empirical and fitted survival functions (denoted as ) for visual comparison. It is important to note that TPBXIID serves as an appropriate model for this dataset.
| 2.3 | 2.7 | 3.2 | 3.7 | 3.9 | 4.3 | 4.5 | 4.8 | 4.8 | 4.9 | 5.1 | 5.2 | 5.5 | 5.5 | 5.8 |
| 6.4 | 6.5 | 6.8 | 6.9 | 7 | 7.3 | 7.4 | 7.7 | 7.9. |
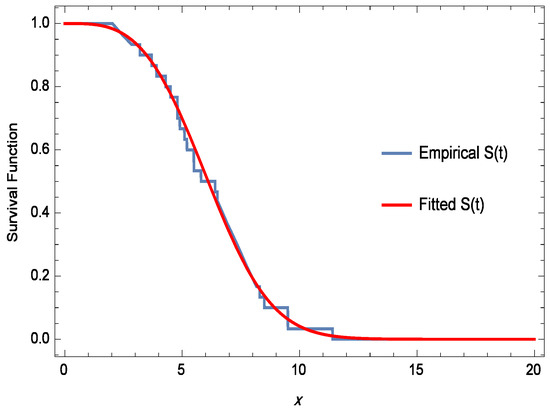
Figure 6.
Empirical and Fitted Survival Functions.
Now, we consider the six cases, as follows:
- I:
- . .
- II:
- . .
- III:
- . .
- IV:
- . .
- V:
- . .
- VI:
- . .
The results obtained in Section 2 were utilized to create 95% one-sample Bayesian prediction intervals for future order statistics , where , using the same sample. Additionally, 95% two-sample Bayesian prediction intervals were constructed for future order statistics , where , based on a future unobserved sample with a size of . To assess the sensitivity of the Bayesian prediction intervals to the hyperparameters , where , two different priors were considered. Firstly, non-informative priors were employed with and . Secondly, informative priors were used with and . The results of the one-sample predictions are displayed in Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6, while the results of the two-sample predictions can be found in Table 7, Table 8, Table 9, Table 10, Table 11 and Table 12.

Table 1.
The 95% one-sample Bayesian prediction intervals for , where , are given for Case I.
Table 2.
The 95% one-sample Bayesian prediction intervals for , where , are given for Case II.
Table 3.
The 95% one-sample Bayesian prediction intervals for , where , are given for Case III.
Table 4.
The 95% one-sample Bayesian prediction intervals for , where , are given for Case IV.
Table 5.
The 95% one-sample Bayesian prediction intervals for , where , are given for Case V.
Table 6.
The 95% one-sample Bayesian prediction intervals for , where , are given for Case VI.
Table 7.
The 95% two-sample for , where , are provided for Case I.
Table 8.
The 95% two-sample for , where , are provided for Case II.
Table 9.
The 95% two-sample for , where , are provided for Case III.
Table 10.
The 95% two-sample for , where , are provided for Case IV.
Table 11.
The 95% two-sample for , where , are provided for Case V.
Table 12.
The 95% two-sample for , where , are provided for Case VI.
7. Simulation
To compare the effectiveness of each approach put forward in this study, simulation results are offered in this study. Comparing the effectiveness of ML estimates with Bayesian estimates for the TPBXIID’s unknown parameters is the main objective. Additionally, three distinct loss functions are used to evaluate the performance of the survival and hazard functions, with a focus on MSEs, CP, and length. The steps taken for the simulation analysis are described in the following way:
- Based on the derived parameter values from Step 1, random samples are produced using the TPBXIID’s inverse cumulative distribution function. After that, these samples have been organised in ascending order.
- The values are calculated, where denotes a estimate (ML estimate or Bayesian estimate).
- A sample is generated using TPBXIID with the following parameter values: , , , and . Steps 1–6 are performed at least 1000 times. The simulation is run with various values for k, r, , and . , , , , and , are estimated using ML estimations, and the MSEs, CP, and length of CIs are calculated for and . Table 13, Table 14 and Table 15, show the results.
Table 13. Evaluation of MSE, CP, and Length of Estimates for parameter at and .
Table 14. Evaluation of MSE, CP, and Length of Estimates for parameter at and .
Table 15. Evaluation of MSE, CP, and Length of Estimates for parameter at and .
- Bayesian estimates are used to estimate , , , , and under the SE, LINEX, and GE loss functions. Informative gamma priors are used for the shape and scale parameters, with specific hyperparameters (, , , , , and ) when and . The results, including 95% CRIs, MSEs, CP, and length, are displayed in Table 13, Table 14 and Table 15.
- Furthermore, the MSE of the estimates is calculated using the following formula:
8. Conclusions
By employing UHCS from TPBXIID, we derive Bayesian prediction intervals for future observations using both one-sample and two-sample prediction techniques. The model incorporates prior beliefs through independent gamma priors for the scale and shape parameters. The computation of Bayesian prediction intervals involves utilizing the Gibbs sampling technique to generate MCMC samples, considering both non-informative and informative priors. The results are demonstrated using a real dataset. In addition, we performed a simulation research to evaluate and contrast how well the suggested approaches performed for various sample sizes ) and various scenarios (I, II, III, IV, V, and VI). We can learn more about the methods’ efficacy based on the earlier results.
- The results presented in Table 1, Table 2, Table 3, Table 4, Table 5, Table 6, Table 7, Table 8, Table 9, Table 10, Table 11 and Table 12 reveal that the length of the prediction intervals increases with higher values of c. Specifically, Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6 indicate that the lower bounds are relatively insensitive to hyper-parameter specifications, while the upper bounds exhibit some sensitivity. Conversely, Table 7, Table 8, Table 9, Table 10, Table 11 and Table 12 demonstrate that both the lower and upper bounds are relatively insensitive to the specification of the hyper-parameters.
- Table 13, Table 14 and Table 15 reveal that the length of the credible intervals (CRIs) for the Bayes estimates of , , and are smaller than the corresponding lengths of the confidence intervals (CIs) of the MLEs. Additionally, the coverage probabilities (CP) of the Bayes estimates are greater than the corresponding CP of the MLEs.
Author Contributions
Methodology, M.M.H. (Mustafa M. Hasaballah); Software, M.M.H. (Mustafa M. Hasaballah); Validation, M.E.B.; Formal analysis, A.A.A.-B.; Resources, A.A.A.-B. and M.M.H. (Md. Moyazzem Hossain); Data curation, A.A.A.-B., M.M.H. (Md. Moyazzem Hossain) and M.E.B.; Writing—original draft, M.M.H. (Mustafa M. Hasaballah); Writing—review & editing, M.E.B. All authors have read and agreed to the published version of the manuscript.
Funding
The authors extend their appreciation to the Deputyship for Research and Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project no. (IFKSUOR3–058–1).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All datasets are reported within the article.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Table A1.
Mathematical notations used in this paper.
Table A1.
Mathematical notations used in this paper.
| Notation | Meaning |
|---|---|
| , , | Parameters of three-parameter Burr-XII distribution |
| Moment | |
| Variance of three-parameter Burr-XII distribution | |
| Inverse of cumulative distribution function | |
| Refers to the total number of failures in the test up to period B | |
| The stopping time point | |
| Fisher information matrix | |
| Hyper-parameters |
Table A2.
Abbreviations used in this paper.
Table A2.
Abbreviations used in this paper.
| Abbreviation | Meaning |
|---|---|
| UHCS | Unified Hybrid Censoring Scheme |
| TPBXIID | Three-Parameter Burr-XII Distribution |
| MCMC | Markov Chain Monte Carlo |
| Probability Density Function | |
| cdf | Cumulative Distribution Function |
| MLEs | Maximum Likelihood Estimators |
| ML | Maximum Likelihood |
| CIs | Confidence Intervals |
| SE | Squared Error Loss Function |
| LINEX | Linear Exponential Loss Function |
| GE | General Entrop Loss Function |
| MSE | Mean Squared Error |
| MAE | Mean Absolute Error |
| CP | Coverage Probability |
| K-S | Kolmogorov-Smirnov |
Appendix B
Appendix C
References
- Balakrishnan, N.; Rasouli, A.; Sanjari Farsipour, N. Exact likelihood inference based on an unified hybrid censored sample from the exponential distribution. J. Stat. Comput. Simul. 2008, 78, 475–788. [Google Scholar] [CrossRef]
- Burr, I.W. Cumulative frequency functions. Ann. Math. Stat. 1942, 13, 215–232. [Google Scholar] [CrossRef]
- Shao, Q. Notes on maximum likelihood estimation for the three-parameter Burr-XII distribution. Comput. Stat. Data Anal. 2004, 45, 675–687. [Google Scholar] [CrossRef]
- Wu, S.J.; Chen, Y.J.; Chang, C.T. Statistical inference based on progressively censored samples with random removals from the Burr type XII distribution. J. Stat. Comput. Simul. 2007, 77, 19–27. [Google Scholar] [CrossRef]
- Silva, G.O.; Ortega, E.M.M.; Garibay, V.C.; Barreto, M.L. Log-Burr-XII regression models with censored data. Comput. Stat. Data Anal. 2008, 52, 3820–3842. [Google Scholar] [CrossRef]
- Ganora, D.; Laio, F. Hydrological applications of the Burr distribution: Practical method for parameter estimation. J. Hydrol. Eng. 2015, 20, 04015024. [Google Scholar] [CrossRef]
- Cook, R.D.; Johnson, M.E. Generalized Burr-Pareto-Logistic distribution with application to a uranium exploration data set. Technometrics 1986, 28, 123–131. [Google Scholar] [CrossRef]
- Zimmer, W.J.J.; Keats, B.; Wang, F.K. The Burr-XII distribution in reliability analysis. J. Qual. Technol. 1998, 30, 386–394. [Google Scholar] [CrossRef]
- Tadikamalla, P.R. A look at the Burr and related distributions. Int. Stat. Rev. 1980, 48, 337–344. [Google Scholar] [CrossRef]
- Belaghi, R.A.; Asl, M.N. Estimation based on progressively Type-I hybrid censored data from the Burr-XII distribution. Stat. Pap. 2019, 60, 761–803. [Google Scholar] [CrossRef]
- Nasir, A.; Yousof, H.M.; Jamal, F.; Korkmaz, M.Ç. The exponentiated Burr-XII power series distribution: Properties and applications. Stats 2019, 2, 15–31. [Google Scholar] [CrossRef]
- Jamal, F.; Chesneau, C.; Nasir, M.A.; Saboor, A.; Altun, E.; Khan, M.A. On a modified Burr-XII distribution having flexible hazard rate shapes. Math. Slovaca 2020, 70, 193–212. [Google Scholar] [CrossRef]
- Sen, T.; Bhattacharya, R.; Pradhan, B.; Tripathi, Y.M. Statistical inference and Bayesian optimal life-testing plans under Type-II unified hybrid censoring scheme. Qual Reliab. Eng Int. 2021, 37, 78–89. [Google Scholar] [CrossRef]
- Dutta, S.; Kayal, S. Bayesian and non-Bayesian inference of Weibull lifetime model based on partially observed competing risks data under unified hybrid censoring scheme. Qual. Reliab. Eng. Int. 2022, 38, 3867–3891. [Google Scholar] [CrossRef]
- Dutta, S.; Ng, H.K.T.; Kayal, S. Inference for a general family of inverted exponentiated distributions under unified hybrid censoring with partially observed competing risks data. J. Comput. Appl. Math. 2023, 422, 114934. [Google Scholar] [CrossRef]
- Sagrillo, M.; Guerra, R.R.; Machado, R.; Bayer, F.M. A generalized control chart for anomaly detection in SAR imagery. Comput. Ind. Eng. 2023, 177, 109030. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Shafay, A.R. One- and two-Sample Bayesian prediction intervals based on Type-II hybrid censored data. Commun. Stat. Theory Method 2012, 41, 1511–1531. [Google Scholar] [CrossRef]
- AL-Hussaini, E.K.; Ahmad, A.A. On Bayesian predictive distributions of generalized order statistics. Metrika 2003, 57, 165–176. [Google Scholar] [CrossRef]
- Shafay, A.R.; Balakrishnan, N. One- and two-sample Bayesian prediction intervals based on Type-I hybrid censored data. Commun. Stat. Simul. Comput. 2012, 41, 65–88. [Google Scholar] [CrossRef]
- Shafay, A.R. Bayesian estimation and prediction based on generalized Type-II hybrid censored sample. J. Stat. Comput. Simul. 2015, 86, 1970–1988. [Google Scholar] [CrossRef]
- Shafay, A.R. Bayesian estimation and prediction based on generalized Type-I hybrid censored sample. Commun. Stat. Theory Methods 2016, 46, 4870–4887. [Google Scholar] [CrossRef]
- Ateya, S.F.; Alghamdi, A.S.; Mousa, A.A.A. Future Failure Time Prediction Based on a Unified Hybrid Censoring Scheme for the Burr-X Model with Engineering Applications. Mathematics 2022, 10, 1450. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equations of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1091. [Google Scholar] [CrossRef]
- Arnold, B.C.; Balakrishnan, N.; Nagaraja, H.N. A First Course in Order Statistics; Wiley: New York, NY, USA, 1992. [Google Scholar]
- Varian, H.R. A Bayesian Approach to Real Estate Assessment; North Holland: Amsterdam, The Netherlands, 1975; pp. 195–208. [Google Scholar]
- Zellner, A. Bayesian estimation and prediction using asymmetric loss functions. J. Am. Assoc. Nurse Pract. 1986, 81, 446–551. [Google Scholar] [CrossRef]
- Basu, A.P.; Ebrahimi, N. Bayesian Approach to Life Testingand Reliability Estimation Using Asymmetric Loss Function. J. Statist. Plann. Infer. 1991, 29, 21–31. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).